
데이터 로딩 엔진
Gato GraphQL은 서버 사이드 컴포넌트를 사용하여 데이터 모델을 표현합니다 (그래프나 트리가 아닙니다). GraphQL 쿼리를 해결하기 위해 데이터 로딩 프로세스가 어떻게 실행되는지 살펴보겠습니다.
데이터를 처리하기 위해서는 컴포넌트를 타입으로 평탄화하고 (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), 컴포넌트 계층에 나타난 순서로 정렬한 다음 (Director, 그 다음 Film, 그 다음 Actor), 「이터레이션」 단위로 처리해야 합니다. 각 이터레이션에서 각 타입의 객체 데이터를 가져옵니다.

서버의 데이터 로딩 엔진은 데이터를 로드하기 위해 다음의 (의사) 알고리즘을 구현해야 합니다.
준비:
- 데이터베이스에서 가져와야 할 객체의 ID 목록을 저장하기 위한 빈 큐를 준비합니다. 타입별로 정리합니다 (각 항목은
[타입 => ID 목록]형식이 됩니다) - 피처드 디렉터 객체의 ID를 가져와서 타입
Director로 큐에 추가합니다
큐에 항목이 없어질 때까지 루프:
- 큐의 첫 번째 항목(타입과 ID 목록, 예:
Director와[2])을 가져오고, 해당 항목을 큐에서 제거합니다 - 타입의
TypeDataLoader객체를 사용하여 데이터베이스에 대해 단일 쿼리를 실행하고, 해당 ID를 가진 해당 타입의 모든 객체를 가져옵니다 - 타입에 관계형 필드가 있는 경우 (예: 타입
Director에는 타입Film의 관계형 필드films가 있음), 현재 이터레이션에서 가져온 모든 객체에서 해당 필드의 모든 ID를 수집하고 (예: 타입Director의 모든 객체에서 필드films에 있는 모든 ID), 해당하는 타입으로 큐에 추가합니다 (예: ID[3, 8]을 타입Film으로).
이터레이션이 완료되면, 모든 타입의 모든 객체 데이터가 로드됩니다.
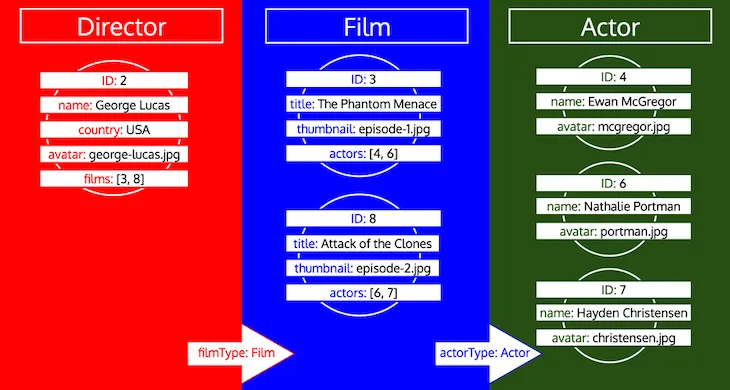
타입의 모든 ID는 해당 타입이 큐에서 처리될 때까지 수집된다는 점에 주목해 주세요. 예를 들어, 타입 Director에 관계형 필드 preferredActors를 추가하면, 이 ID들은 타입 Actor로 큐에 추가되고, 타입 Film의 필드 actors에서 온 ID들과 함께 처리됩니다.
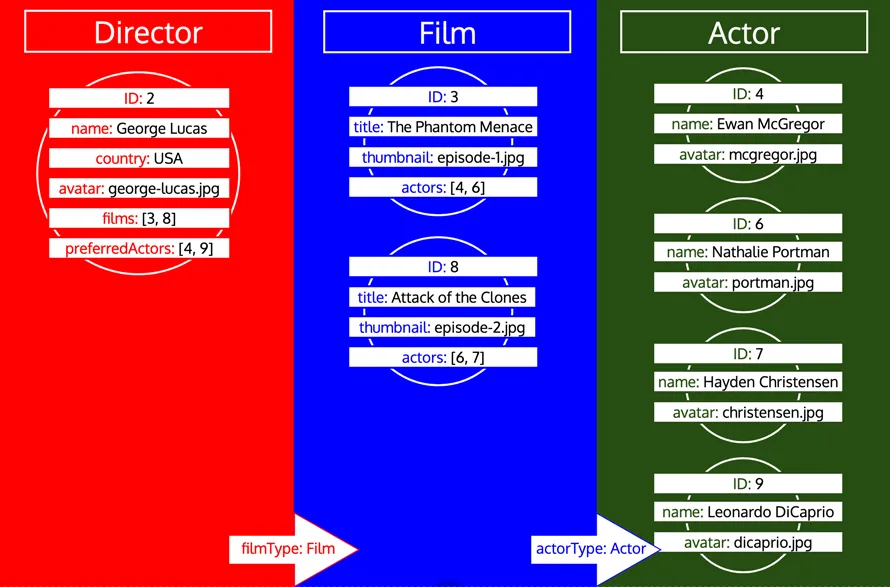
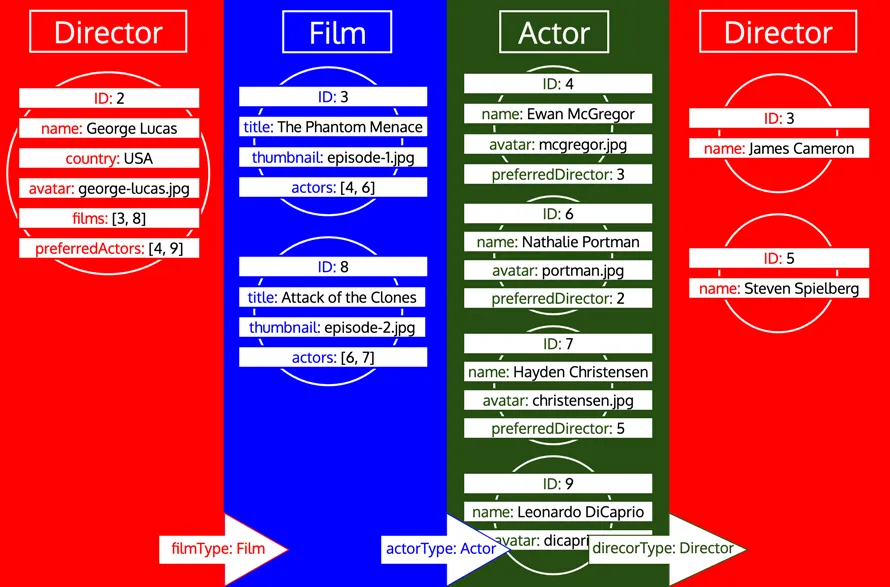
단, 어떤 타입이 이미 처리되었더라도 해당 타입에서 추가 데이터를 로드해야 하는 경우에는 해당 타입에 대한 새로운 이터레이션이 수행됩니다. 예를 들어, Author 타입에 관계형 필드 preferredDirector를 추가하면, 타입 Director가 다시 큐에 추가됩니다.
모든 객체 데이터를 가져왔으니, 이제 GraphQL 쿼리를 반영한 예상 응답 형식으로 데이터를 변환해야 합니다. 그러나 보시다시피 데이터에는 필요한 트리 구조가 없습니다. 대신, 관계형 필드에는 중첩된 객체에 대한 ID가 포함되어 있어, 관계형 데이터베이스에서 데이터가 표현되는 방식을 모방합니다. 따라서 이 비교에 따르면, 각 타입에 대해 가져온 데이터는 다음과 같이 테이블로 표현할 수 있습니다.
타입 Director의 테이블:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
타입 Film의 테이블:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
타입 Actor의 테이블:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
모든 데이터가 테이블로 정리되고, 각 타입이 서로 어떻게 관련되어 있는지 알면 (즉, Director는 필드 films를 통해 Film을 참조하고, Film은 필드 actors를 통해 Actor를 참조함), GraphQL 서버는 데이터를 예상되는 트리 형식으로 쉽게 변환할 수 있습니다.
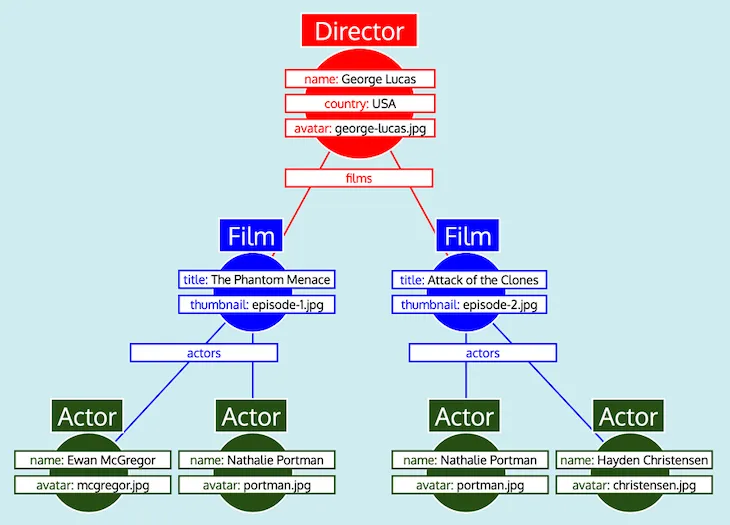
마지막으로, GraphQL 서버는 트리를 출력합니다. 이것은 예상되는 응답의 형식을 가지고 있습니다.
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}솔루션의 시간 복잡도 분석
데이터 로딩 알고리즘의 빅O 표기법을 분석하여, 입력 수가 증가함에 따라 데이터베이스에 실행되는 쿼리 수가 어떻게 증가하는지 이해하고, 이 솔루션이 높은 성능을 발휘함을 확인해 보겠습니다.
데이터 로딩 엔진은 각 타입에 대응하는 이터레이션에서 데이터를 로드합니다. 이터레이션을 시작할 시점에는 가져와야 할 모든 객체의 모든 ID 목록이 이미 준비되어 있으므로, 해당 객체의 모든 데이터를 가져오기 위해 단 1번의 쿼리를 실행할 수 있습니다. 따라서 데이터베이스에 대한 쿼리 수는 쿼리에 포함된 타입 수에 비례하여 선형적으로 증가합니다. 즉, 시간 복잡도는 O(n)이며, n은 쿼리 내 타입의 수입니다 (단, 어떤 타입이 여러 번 이터레이션되는 경우에는 n에 여러 번 더해집니다).
이 솔루션은 매우 높은 성능을 발휘하며, 그래프를 처리할 때 예상되는 지수적 복잡도나 트리를 처리할 때 예상되는 로그적 복잡도보다 훨씬 뛰어납니다.
구현된 PHP 코드
데이터 로딩 프로세스는 패키지 Component Model의 클래스 Engine에 있는 함수 getComponentData에서 수행됩니다.