
필드 해결 순서 조작
Multiple Query Execution이 제공하는 @export 디렉티브의 목적은 필드(또는 필드 집합)의 값을 변수로 내보내어 쿼리 내 다른 곳에서 사용하는 것입니다.
변수로의 값 내보내기가 이루어지기 전에 변수를 읽으면 이 디렉티브는 작동하지 않습니다. 따라서 엔진은 필드 실행 순서를 제어하는 방법을 제공해야 합니다.
Gato GraphQL은 쿼리 자체를 통해 필드 실행 순서를 조작하는 방법을 제공합니다. 엔진은 각 타입별로 이터레이션하면서 데이터를 로드합니다. 먼저 쿼리에서 처음 만나는 타입의 모든 필드를 해결하고, 다음으로 두 번째 타입의 모든 필드를 해결하는 방식으로, 처리할 타입이 없을 때까지 계속합니다.
예를 들어, Director, Film, Actor 타입의 객체가 포함된 다음 쿼리를 살펴보겠습니다:
{
directors {
name
films {
title
actors {
name
}
}
}
}...는 GraphQL 엔진에 의해 다음 순서로 해결됩니다:

처리가 완료된 타입이 미로드 데이터(예: 추가 객체, 또는 이미 로드된 객체의 추가 필드)를 가져오기 위해 쿼리에서 다시 참조되면, 해당 타입은 이터레이션 목록의 끝에 다시 추가됩니다.
예를 들어, Actor의 preferredDirector 필드(Director 타입의 객체를 반환)도 다음과 같이 쿼리하는 경우:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...그러면 GraphQL 엔진은 쿼리를 다음 순서로 처리합니다:

단일 쿼리에서 @export를 실행할 때 이것이 어떻게 작동하는지 살펴보겠습니다. 첫 번째 시도로, 필드의 실행 순서를 고려하지 않고 평소대로 쿼리를 작성합니다:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}쿼리를 실행하면 다음 응답이 반환됩니다:
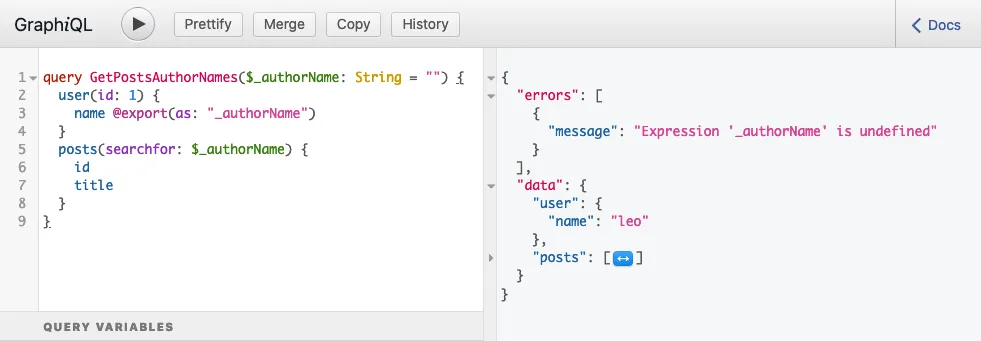
...다음 오류가 포함되어 있습니다:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}이 오류는 변수 $authorName이 읽혀질 시점에 아직 설정되지 않아 undefined 상태였음을 의미합니다.
이것이 왜 발생하는지 살펴보겠습니다. 먼저, 쿼리에 등장하는 타입을 아래 주석으로 분석합니다:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}타입을 처리하고 데이터를 로드하기 위해, 데이터 로딩 엔진은 쿼리 타입 Root를 FIFO(First-In, First-Out: 선입선출) 목록에 추가합니다. 이로써 알고리즘에 전달되는 초기 목록은 [Root]가 되며, 그 후 타입을 순차적으로 이터레이션합니다:
| # | 작업 | 목록 |
|---|---|---|
| 0 | FIFO 목록 준비 | [Root] |
| 1a | 목록의 첫 번째 타입(Root) 꺼내기 | [] |
| 1b | Root 타입에서 쿼리된 모든 필드 처리:→ user(by: {id: 1})→ posts(filter: { search: $authorName })해당 타입( User와 Post)을 목록에 추가 | [User, Post] |
| 2a | 목록의 첫 번째 타입(User) 꺼내기 | [Post] |
| 2b | User 타입에서 쿼리된 필드 처리:→ name @export(as: "authorName")스칼라 타입( String)이므로 목록에 추가할 필요 없음 | [Post] |
| 3a | 목록의 첫 번째 타입(Post) 꺼내기 | [] |
| 3b | Post 타입에서 쿼리된 모든 필드 처리:→ id→ title스칼라 타입( ID와 String)이므로 목록에 추가할 필요 없음 | [] |
| 4 | 목록이 비어 이터레이션이 종료됩니다. |
여기서 문제를 확인할 수 있습니다: @export는 2b 단계에서 실행되지만, 읽기는 1b 단계에서 이루어졌습니다.
이 지점에서 필드 실행 흐름을 제어해야 합니다. 구현된 해결책은 내보낸 변수가 읽히는 시점을 지연시키는 것으로, Root 타입에서 self 필드를 인위적으로 쿼리함으로써 실현됩니다.
self 필드는 그 이름이 나타내듯이 동일한 객체를 반환합니다. Root 객체에 적용하면 동일한 Root 객체를 반환합니다. "루트 객체를 이미 가지고 있는데 왜 다시 가져와야 하는가?"라고 의문을 품을 수 있습니다. 왜냐하면, 엔진의 알고리즘이 이 새로운 Root 참조를 FIFO 목록의 끝에 추가해야 하며, 이를 통해 쿼리된 필드를 각 이터레이션의 전후에 의도적으로 배분할 수 있기 때문입니다.
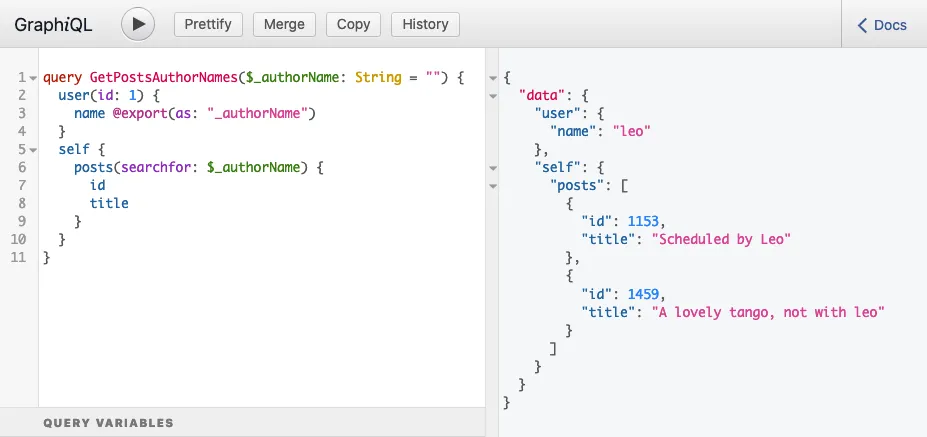
그 때문에 위 쿼리에서 posts(filter:{ search: $authorName }) 필드가 self 필드 내부에 배치되어 있으며, 쿼리를 실행하면 예상된 응답이 반환됩니다:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
이 쿼리에서 타입이 처리되는 순서를 확인하여 왜 잘 작동하는지 이해해 보겠습니다:
| # | 작업 | 목록 |
|---|---|---|
| 0 | FIFO 목록 준비 | [Root] |
| 1a | 목록의 첫 번째 타입(Root) 꺼내기 | [] |
| 1b | Root 타입에서 쿼리된 모든 필드 처리:→ user(by: {id: 1})→ self해당 타입( User와 Root)을 목록에 추가 | [User, Root] |
| 2a | 목록의 첫 번째 타입(User) 꺼내기 | [Root] |
| 2b | User 타입에서 쿼리된 필드 처리:→ name @export(as: "authorName")스칼라 타입( String)이므로 목록에 추가할 필요 없음 | [Root] |
| 3a | 목록의 첫 번째 타입(Root) 꺼내기 | [] |
| 3b | Root 타입에서 쿼리된 필드 처리:→ posts(filter:{ search: $authorName })해당 타입( Post)을 목록에 추가 | [Post] |
| 4a | 목록의 첫 번째 타입(Post) 꺼내기 | [] |
| 4b | Post 타입에서 쿼리된 모든 필드 처리:→ id→ title스칼라 타입( ID와 String)이므로 목록에 추가할 필요 없음 | [] |
| 5 | 목록이 비어 이터레이션이 종료됩니다. |
이제 문제가 해결된 것을 확인할 수 있습니다: @export는 2b 단계에서 실행되고, 3b 단계에서 읽힙니다.
Multiple Query Execution은 쿼리 분리를 수행할 때 바로 이것을 실행합니다: GraphQL 문서를 변환하여 self 필드를 추가함으로써, 각 오퍼레이션의 필드가 이전 모든 오퍼레이션의 모든 필드가 해결된 후에만 실행되도록 합니다.