
디렉티브 파이프라인
디렉티브는 파이프라인에 배치되어 순서대로 실행됩니다. 초기 설계는 다음과 같이 단순합니다.

이 아키텍처에서는:
- 파이프라인의 입력은 필드 리졸버가 제공하는 필드의 값입니다
- 각 디렉티브는 로직을 실행하고 결과를 파이프라인의 다음 디렉티브로 전달합니다
- 파이프라인의 출력은 모든 디렉티브에 의해 처리된 후의 해결된 필드 값입니다
그러나 이 아키텍처는 GraphQL의 능력을 최대한 활용하고 있다고 볼 수 없습니다. 아래에서는 Gato GraphQL에 실제로 구현된 설계에 이르기까지 실제 디렉티브 파이프라인의 모든 단계를 설명합니다.
쿼리 해결의 구성 요소로서의 디렉티브
처음에는 GraphQL 서버가 어떤 메커니즘을 통해 필드를 해결한 후, 그 값을 디렉티브 파이프라인의 입력으로 전달하는 방식을 고려할 수 있습니다.
그러나 모든 것을 처리하는 단일 메커니즘을 갖는 것이 훨씬 더 단순합니다. 필드 리졸버 호출(필드의 유효성 검사와 필드 해결 모두)은 이미 디렉티브 파이프라인을 통해 수행할 수 있습니다. 이 경우 디렉티브 파이프라인이 쿼리를 해결하는 유일한 메커니즘이 됩니다.
이러한 이유로 Gato GraphQL 서버에는 두 가지 특별한 디렉티브가 제공됩니다.
@validate는 필드 리졸버를 호출하여 필드가 해결될 수 있는지 유효성을 검사합니다(예: 구문이 올바른지, 필드가 존재하는지 등)- 유효성 검사가 성공하면
@resolveValueAndMerge가 필드 리졸버를 호출하여 필드를 해결하고, 그 값을 응답 객체에 병합합니다
이 두 가지는 특별한 유형인 "시스템" 디렉티브입니다. GraphQL 엔진 전용으로 예약되어 있으며, 모든 필드에서 암묵적으로 사용됩니다. (반면 표준 디렉티브는 명시적입니다. 사용자가 쿼리에 추가합니다.)
이 두 디렉티브를 사용하면 다음 쿼리는:
query {
field1
field2 @directiveA
}...다음과 같이 해결됩니다:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}파이프라인은 이제 다음과 같이 됩니다(파이프라인이 초기 해결 값이 아닌 필드를 입력으로 받는다는 점에 유의하십시오):

파이프라인 슬롯
디렉티브는 일반적으로 @resolveValueAndMerge 이후에 실행됩니다. 이는 해결된 필드의 값을 업데이트하는 경우가 많기 때문입니다. 그러나 @validate 이전이나 @validate와 @resolveValueAndMerge 사이에 실행되어야 하는 디렉티브도 있습니다.
예를 들어:
- 필드를 해결하는 데 걸리는 시간을 측정하기 위해, 디렉티브
@traceExecutionTime은 파이프라인의 시작 부분에 서브디렉티브@startTracingExecutionTime을, 끝 부분에@endTracingExecutionTime을 배치하여 필드가 해결되기 전후의 현재 시간을 가져올 수 있습니다 - 디렉티브
@cache는@resolveValueAndMerge를 실행하기 전에 요청된 필드가 캐시되어 있는지 확인하고, 이미 캐시된 경우 해당 응답을 반환해야 합니다
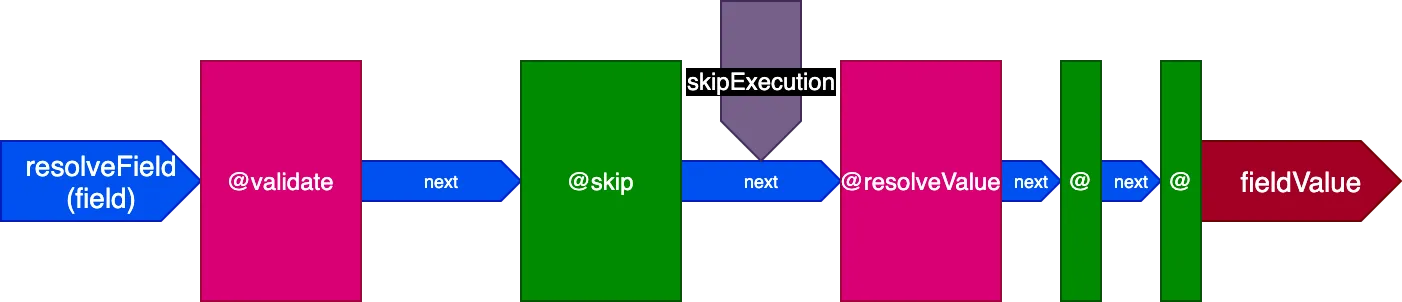
파이프라인은 클래스 PipelinePositions를 통해 5가지 다른 슬롯을 제공하며, 디렉티브는 어느 슬롯에서 실행되어야 하는지를 지정합니다.
"beginning"슬롯: 맨 처음 위치"before-validate"슬롯: 유효성 검사가 수행되기 전"middle"슬롯: 유효성 검사 이후, 필드 해결 이전"after-resolve"슬롯: 필드 해결 이후"end"슬롯: 맨 마지막 위치
디렉티브 파이프라인은 이제 다음과 같이 됩니다(단순화를 위해 3개의 단계만 고려):

이 아키텍처에서 디렉티브 @skip과 @include가 얼마나 쉽게 구현될 수 있는지 주목하십시오. "middle" 슬롯에 배치됨으로써, 플래그 skipExecution을 true로 설정하여 디렉티브 @resolveValueAndMerge(및 파이프라인 내 이후 단계의 모든 디렉티브)에 실행하지 않도록 알릴 수 있습니다.
단일 호출로 여러 필드에 디렉티브 실행하기
지금까지는 디렉티브 파이프라인의 입력으로 단일 필드를 고려했습니다. 그러나 일반적인 GraphQL 쿼리에서는 디렉티브를 실행할 여러 필드를 받게 됩니다.
예를 들어, 아래 쿼리에서 디렉티브 @upperCase는 필드 "field1"과 "field2"에 대해 실행됩니다.
query {
field1 @upperCase
field2 @upperCase
field3
}또한 GraphQL 엔진은 쿼리의 모든 필드에 시스템 디렉티브 @validate와 @resolveValueAndMerge를 추가하므로, 다음 쿼리는:
query {
field1
field2
field3
}...다음 쿼리로 해결됩니다:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}따라서 시스템 디렉티브는 항상 모든 필드를 입력으로 받게 됩니다.
그 결과, 디렉티브 파이프라인은 한 번에 하나가 아닌 여러 필드를 입력으로 받도록 설계되어 있습니다.

이 아키텍처는 더 효율적입니다. 모든 필드에 대해 디렉티브를 한 번만 실행하는 것이 필드마다 한 번씩 실행하는 것보다 빠르며, 동일한 결과를 생성하기 때문입니다.
예를 들어, 스키마에 대한 접근을 허용하기 위해 사용자가 로그인했는지 유효성을 검사할 때, 그 작업은 한 번만 실행할 수 있습니다. 다음 코드를 실행하는 것은:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}이 코드를 실행하는 것보다 더 효율적입니다:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}isUserLoggedIn과 같은 로컬 함수를 호출할 때는 큰 차이가 없을 수 있지만, GraphQL을 통해 REST 엔드포인트를 해결하는 것처럼 외부 서비스와 연동할 때는 큰 차이가 생깁니다. 이러한 경우 함수를 여러 번이 아닌 한 번만 실행하는 것이 특정 기능을 제공할 수 있는지 없는지의 차이를 만들 수 있습니다.
예를 살펴보겠습니다. @translate 디렉티브를 통해 Google Translate와 연동할 때, GraphQL API는 네트워크를 통해 연결을 설정해야 합니다. 따라서 다음 코드를 실행하는 것이 가장 빠릅니다:
googleTranslateFields([$field1, $field2, $field3]);반면 함수를 개별적으로 여러 번 실행하면 더 높은 레이턴시가 발생하여 API 성능이 저하됩니다. 3개의 문자열을 번역하는 경우(필드가 번역할 문자열)에는 큰 차이가 없을 수 있지만, 100개 이상의 문자열에서는 확실히 영향이 있습니다:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);또한 모든 입력을 한 번에 함수에 전달하면 각 필드를 독립적으로 처리하는 것보다 더 나은 응답을 얻을 수 있습니다. 다시 Google Translate를 예로 들면, 서비스에 제공하는 데이터가 많을수록 번역이 더 정확해집니다.
예를 들어, 아래 코드를 실행하면:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");첫 번째 개별 실행에서 Google은 "fork"의 문맥을 모르기 때문에 식사용 포크, 도로의 분기, 또는 다른 의미로 응답할 수 있습니다. 그러나 대신 다음과 같이 실행하면:
googleTranslate(["fork", "road", "sign"]);이 더 많은 정보를 통해 Google은 "fork"가 도로의 분기를 가리킨다고 추론하여 정확한 번역을 반환할 수 있습니다.
이러한 이유로 파이프라인 내의 디렉티브는 입력 필드를 모두 함께 받으며, 각 디렉티브는 이러한 입력에 대해 로직을 실행하는 최선의 방법을 결정할 수 있습니다(입력마다 한 번 실행, 모든 입력을 포함한 한 번 실행, 또는 그 사이의 방법).
파이프라인은 이제 다음과 같이 됩니다:
전체 쿼리에 대해 단일 디렉티브 파이프라인 실행하기
방금 디렉티브마다 여러 필드를 실행하는 것이 합리적임을 알았습니다. 그러나 이것은 모든 필드에 동일한 디렉티브가 적용된 경우에만 잘 작동합니다. 디렉티브가 다른 경우 구현을 어렵게 만드는 복잡성이 증가하고, 얻은 이점의 일부가 줄어들 수 있습니다.
이것이 어떻게 발생하는지 살펴보겠습니다. 다음 쿼리를 고려하십시오:
query {
field1 @directiveA
field2
field3
}이 디렉티브는 다음과 동일합니다:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}이 시나리오에서 필드 field2와 field3는 동일한 디렉티브 세트를 가지고, field1은 다른 세트를 가지므로 쿼리를 해결하기 위해 2개의 다른 파이프라인을 생성해야 합니다:
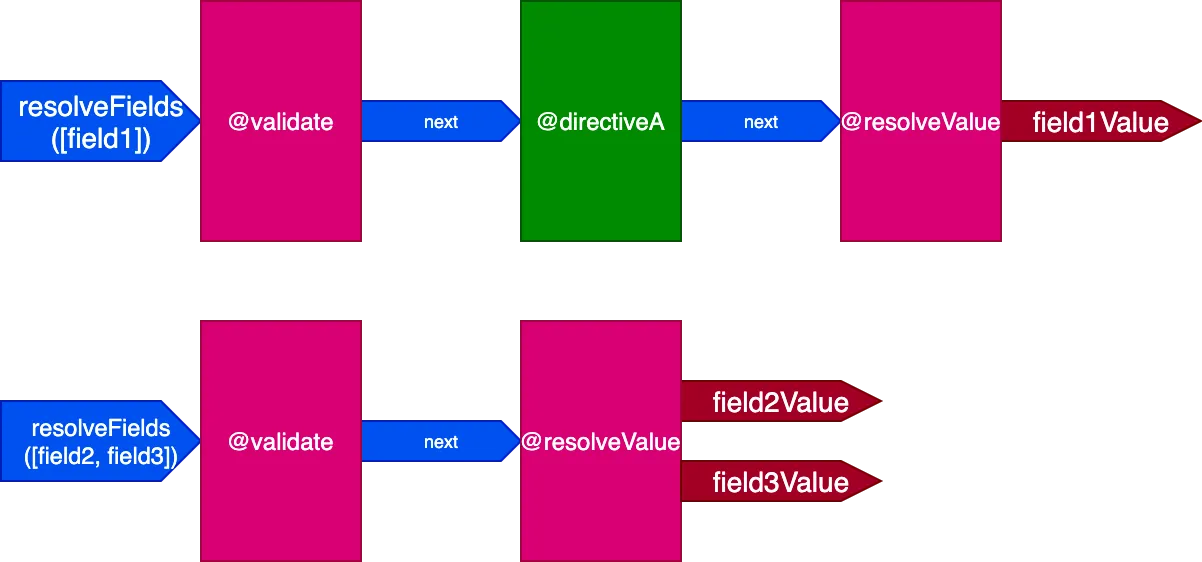
모든 필드가 고유한 디렉티브 세트를 가질 때 효과는 더욱 두드러집니다. 다음 쿼리를 고려하십시오:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}이것은 다음과 동일합니다:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}이 상황에서는 3개의 필드를 처리하기 위해 3개의 파이프라인이 필요합니다:
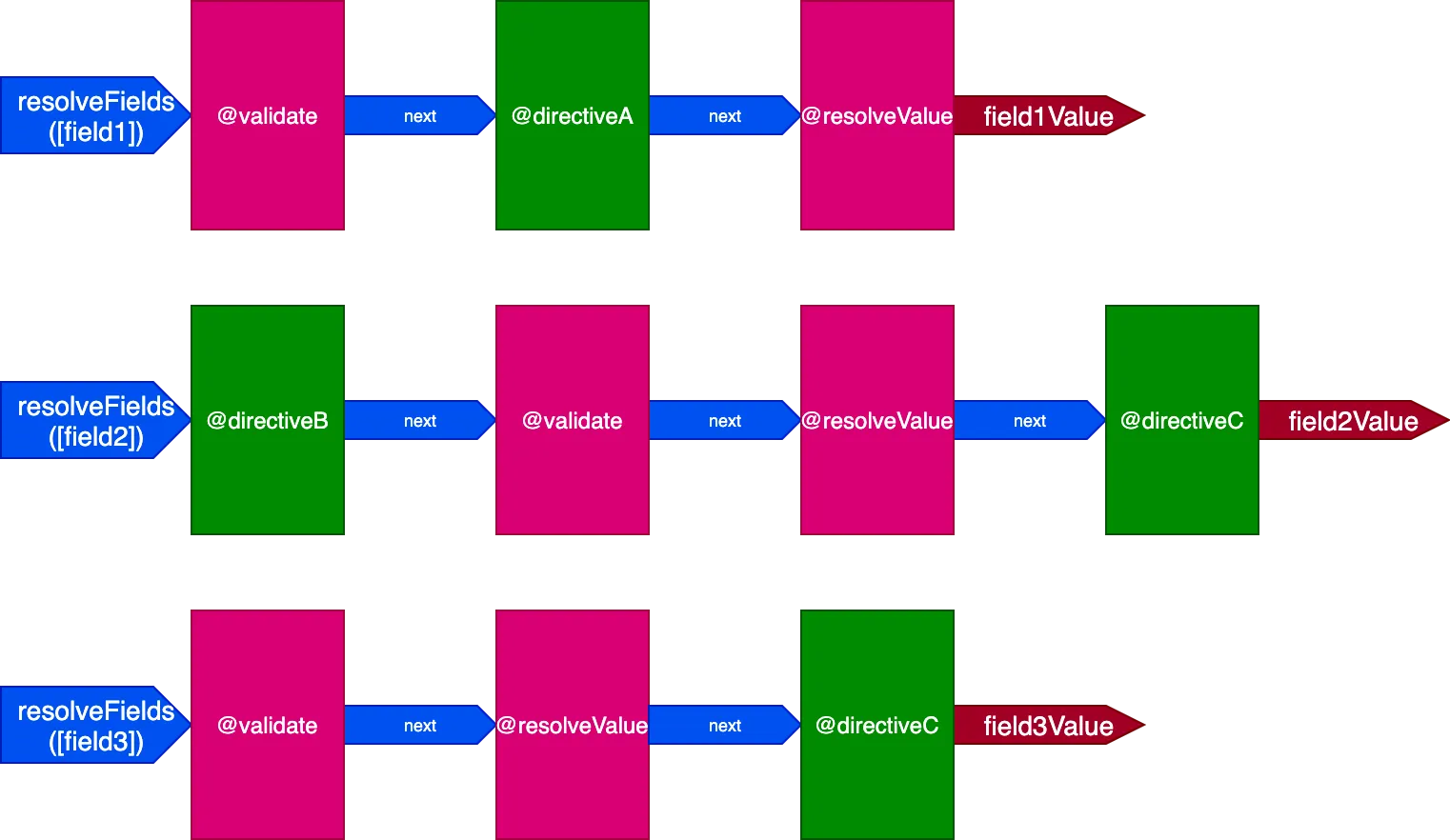
이 경우, 디렉티브 @validate와 @resolveValueAndMerge는 3개의 필드 모두에 적용되지만, 3개의 다른 디렉티브 파이프라인을 통해 실행되기 때문에 서로 독립적으로 실행됩니다. 이로 인해 디렉티브가 한 번에 단일 항목에 대해 실행되는 상황으로 돌아가게 됩니다.
이 문제의 해결책은 여러 파이프라인을 생성하는 것을 피하고, 모든 필드에 대해 단일 파이프라인으로 처리하는 것입니다. 그 결과, 엔진은 더 이상 필드를 파이프라인의 입력으로 전달하지 않습니다. 단일 파이프라인 내의 모든 디렉티브가 동일한 필드 세트와 상호작용하는 것은 아니기 때문입니다. 대신, 각 디렉티브는 자신의 입력으로 고유한 필드 목록을 받아야 합니다.
다음 쿼리의 경우:
query {
field1 @directiveA
field2
field3
}...디렉티브 @validate와 @resolveValueAndMerge는 3개의 필드 모두를 입력으로 받고, directiveA는 "field1"만 받습니다:
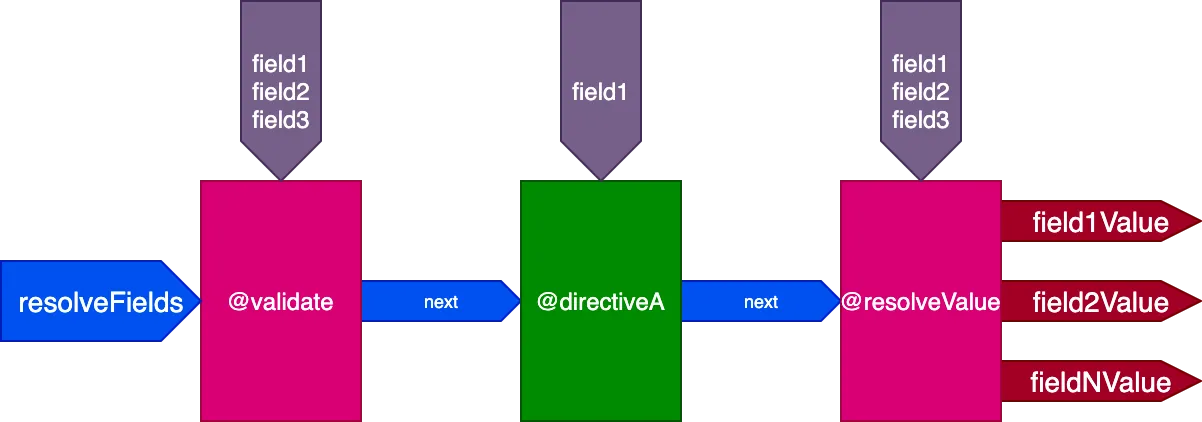
다음 쿼리의 경우:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...디렉티브 @validate와 @resolveValueAndMerge는 3개의 필드 모두를 입력으로 받고, directiveA는 "field1"만을, directiveB는 "field2"만을, directiveC는 "field2"와 "field3"을 받습니다:
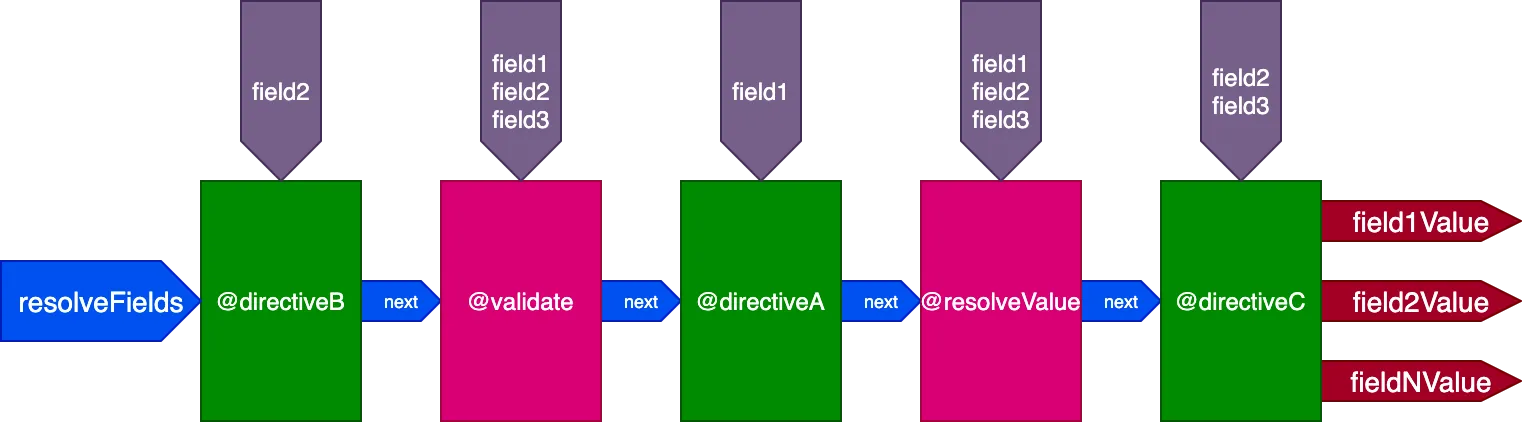
ID별로 디렉티브 실행 제어하기
지금까지 어떤 단계의 디렉티브는 플래그 skipExecution을 통해 이후 단계 디렉티브의 실행에 영향을 줄 수 있었습니다. 그러나 이 플래그는 모든 경우에 충분히 세밀하지 않습니다.
예를 들어, "end" 슬롯에 배치되어 필드 값을 저장하는 디렉티브 @cache를 고려해 보겠습니다. 다음 번에 필드가 쿼리될 때, "middle" 슬롯에 배치된 디렉티브 @getCache를 통해 캐시에서 해당 값을 가져올 수 있습니다:
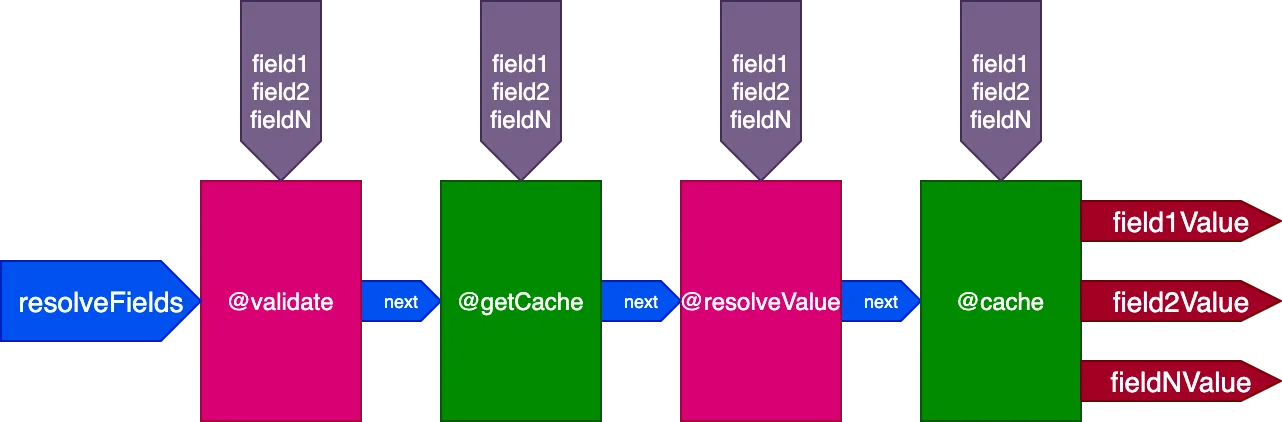
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}서버는 2개의 레코드를 가져와 캐시합니다. 그런 다음 동일한 쿼리를 4개의 레코드에 적용하여 실행합니다:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}이 두 번째 쿼리를 실행할 때, 첫 번째 쿼리의 2개 레코드는 이미 캐시되어 있지만 나머지 2개는 캐시되지 않았습니다. 그러나 플래그 skipExecution을 사용하려면 4개의 레코드 모두가 이미 캐시되어 있어야 합니다. 처음 2개의 레코드는 캐시에서 가져오고, 나머지 2개의 레코드만 해결할 수 있다면 더 좋을 것입니다.
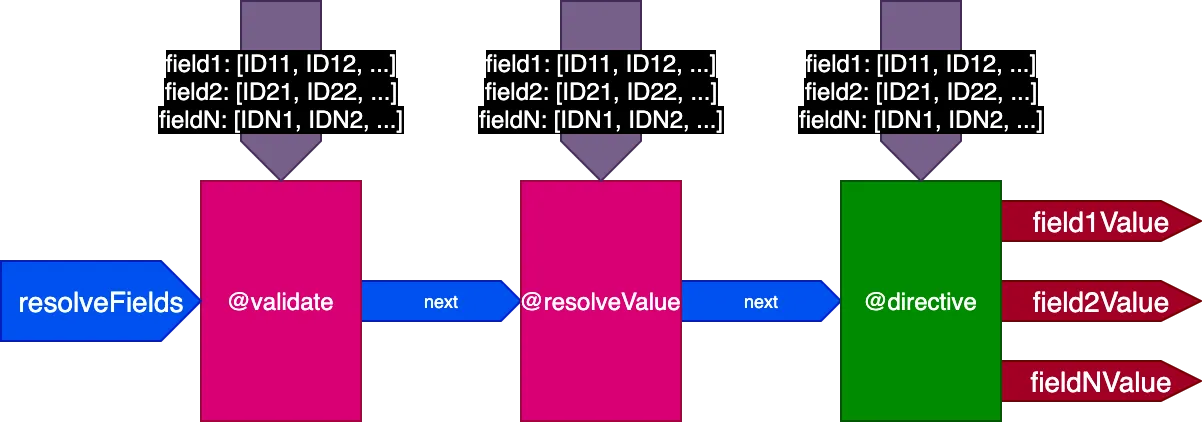
그래서 파이프라인의 설계를 다시 업데이트합니다. 플래그 skipExecution을 폐기하고, 대신 입력 객체 fieldIDs를 통해 디렉티브를 적용해야 하는 필드별 객체 ID 목록을 각 디렉티브에 전달합니다:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}변수 fieldIDs는 각 디렉티브에 고유하며, 모든 디렉티브는 이후 단계의 모든 디렉티브에 대한 fieldIDs 인스턴스를 수정할 수 있습니다. 이를 통해 skipExecution을 ID별로 세밀하게 수행할 수 있습니다. 스택 내 이후 모든 디렉티브의 fieldIDs에서 해당 ID를 제거하기만 하면 됩니다.
파이프라인은 이제 다음과 같이 됩니다:
이전 예제에 적용하면, 2개의 레코드를 번역하는 첫 번째 쿼리를 실행할 때 파이프라인은 다음과 같습니다:
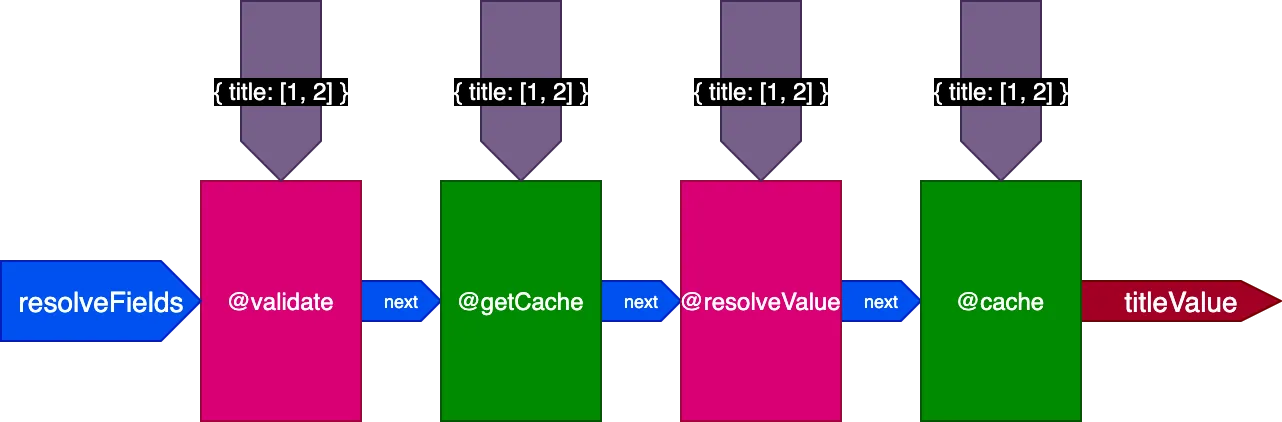
4개의 레코드를 번역하는 두 번째 쿼리를 실행할 때, 디렉티브 @getCache는 4개의 레코드 모두의 ID를 받지만, @resolveValueAndMerge와 @cache는 캐시되지 않은 마지막 2개의 레코드의 ID만 받습니다:
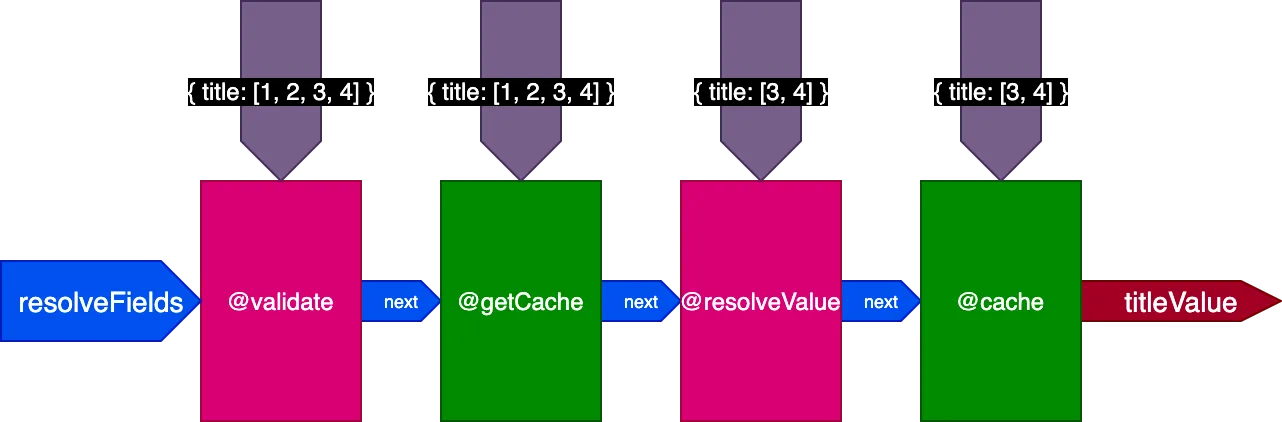
모든 것을 종합하면
이것이 디렉티브 파이프라인의 최종 설계입니다:
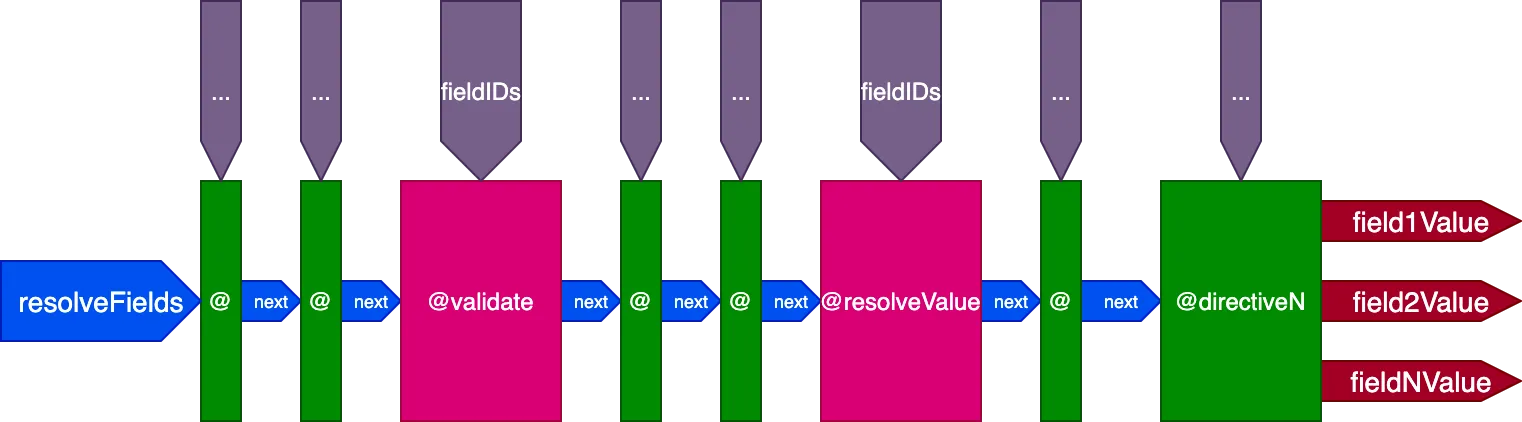
요약하면, 그 특징은 다음과 같습니다:
- 필드 리졸버는 디렉티브 파이프라인 내에서 디렉티브
@validate와@resolveValueAndMerge를 통해 호출됩니다 - 디렉티브는 5개의 슬롯 중 어느 곳에나 배치할 수 있습니다:
"beginning","before-validate","middle","after-validate","end" - 디렉티브는 단일 호출로 여러 필드를 해결합니다
- 단일 파이프라인에 쿼리에 관여하는 모든 디렉티브가 포함됩니다
- 각 디렉티브는 변수
fieldIDs를 통해 필드별로 해결해야 할 ID의 고유한 세트를 받습니다 - 디렉티브는 파이프라인 내 이후 단계의 모든 디렉티브에 대한 변수
fieldIDs를 수정할 수 있습니다