Persisted Queries
GraphQL 쿼리를 사용하여 REST와 같은 사전 정의된 엔드포인트를 생성하고, 두 API의 장점을 모두 활용하세요.
설명
REST에서는 여러 엔드포인트를 생성하며, 각 엔드포인트는 사전 정의된 데이터 집합을 반환합니다.
| 장점 | 단점 |
|---|---|
| ✅ 단순합니다 | ❌ 모든 엔드포인트를 생성하기가 번거롭습니다 |
✅ GET 또는 POST로 접근할 수 있습니다 | ❌ 엔드포인트가 준비될 때까지 프로젝트가 병목 현상을 겪을 수 있습니다 |
| ✅ 서버 또는 CDN에서 캐시할 수 있습니다 | ❌ 문서화가 필수입니다 |
| ✅ 안전합니다: 의도한 데이터만 공개됩니다 | ❌ 애플리케이션이 모든 데이터를 가져오기 위해 여러 번 요청해야 할 수 있어(주로 모바일 앱에서) 속도가 느릴 수 있습니다 |
GraphQL에서는 단일 엔드포인트에 어떤 쿼리든 제공할 수 있으며, 요청된 데이터만 정확하게 반환됩니다.
| 장점 | 단점 |
|---|---|
| ✅ 데이터의 언더/오버 페칭이 없습니다 | ❌ POST로만 접근할 수 있습니다 |
| ✅ 모든 데이터를 한 번의 요청으로 가져올 수 있어 빠릅니다 | ❌ 서버 또는 CDN에서 캐시할 수 없어 본래보다 느리고 비용이 더 많이 듭니다 |
| ✅ 프로젝트의 빠른 반복이 가능합니다 | ❌ 파일 업로드나 캐싱 등 바퀴를 다시 발명해야 할 수 있습니다 |
| ✅ 자체 문서화가 가능합니다 | ❌ N+1 문제 등 추가적인 복잡성에 대처해야 합니다 |
| ✅ 쿼리용 에디터(GraphiQL)를 제공하여 작업을 간소화합니다 |
Persisted queries는 이 두 가지 접근 방식을 결합합니다:
- GraphQL을 사용하여 쿼리를 생성하고 해결합니다
- 단, 단일 엔드포인트를 노출하는 대신, 각 사전 정의된 쿼리를 고유한 엔드포인트로 노출합니다
따라서 REST처럼 사전 정의된 데이터를 가진 여러 엔드포인트를 얻을 수 있으며, GraphQL을 사용하여 생성되므로 각각의 장점을 취하고 단점을 피할 수 있습니다:
| 장점 | 단점 |
|---|---|
✅ GET 또는 POST로 접근할 수 있습니다 | |
| ✅ 서버 또는 CDN에서 캐시할 수 있습니다 | |
| ✅ 안전합니다: 의도한 데이터만 공개됩니다 | |
| ✅ 데이터의 언더/오버 페칭이 없습니다 | |
| ✅ 모든 데이터를 한 번의 요청으로 가져올 수 있어 빠릅니다 | POST로만 접근할 수 있습니다 |
| ✅ 프로젝트의 빠른 반복이 가능합니다 | |
| ✅ 자체 문서화가 가능합니다 | |
| ✅ 쿼리용 에디터(GraphiQL)를 제공하여 작업을 간소화합니다 |

Persisted Query 실행
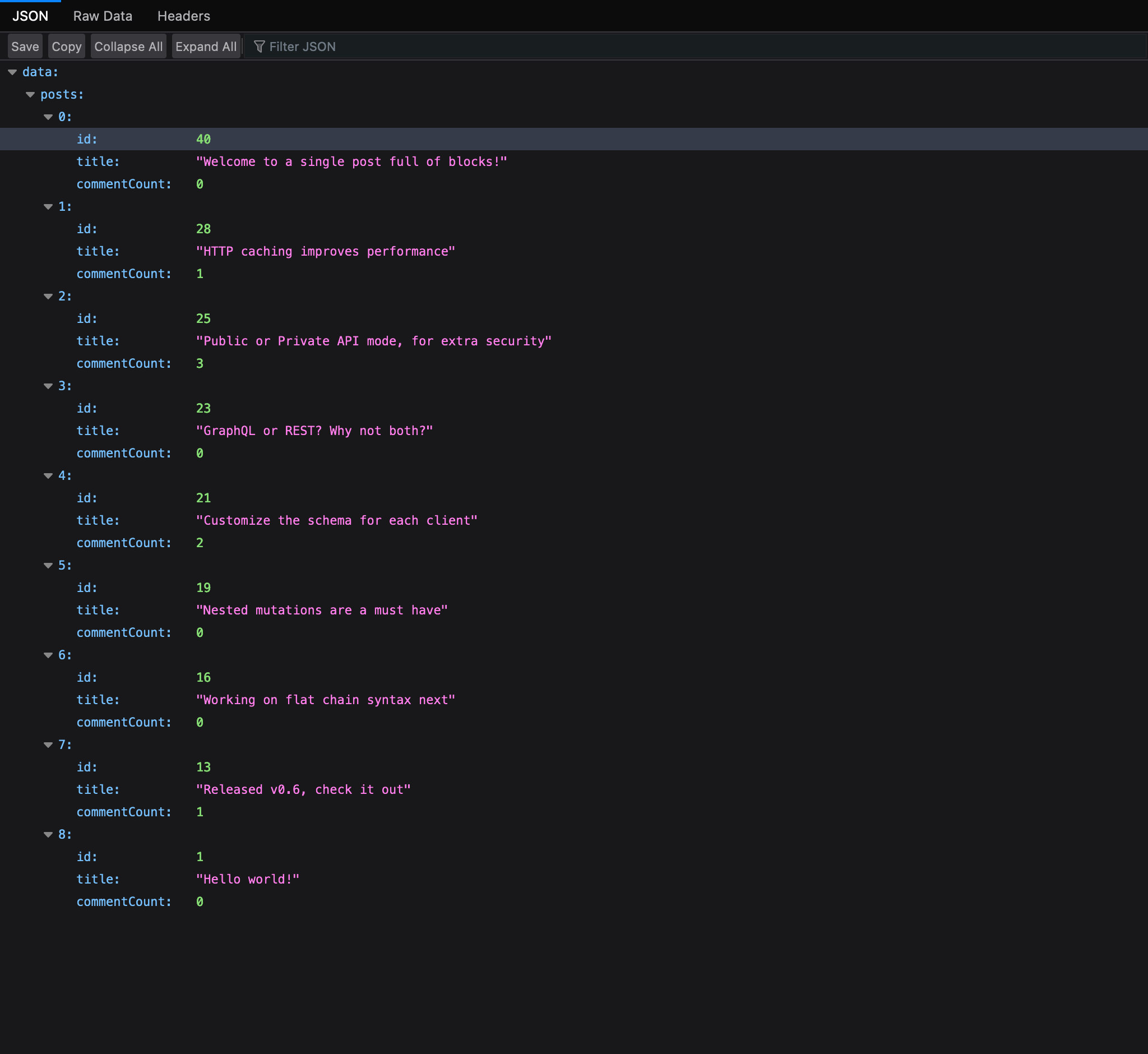
persisted query가 게시되면, 해당 퍼머링크를 통해 실행할 수 있습니다.
persisted query는 GET으로 접근하므로 브라우저에서 직접 실행할 수 있으며, 요청한 데이터를 JSON 형식으로 얻을 수 있습니다:
Persisted Query 생성
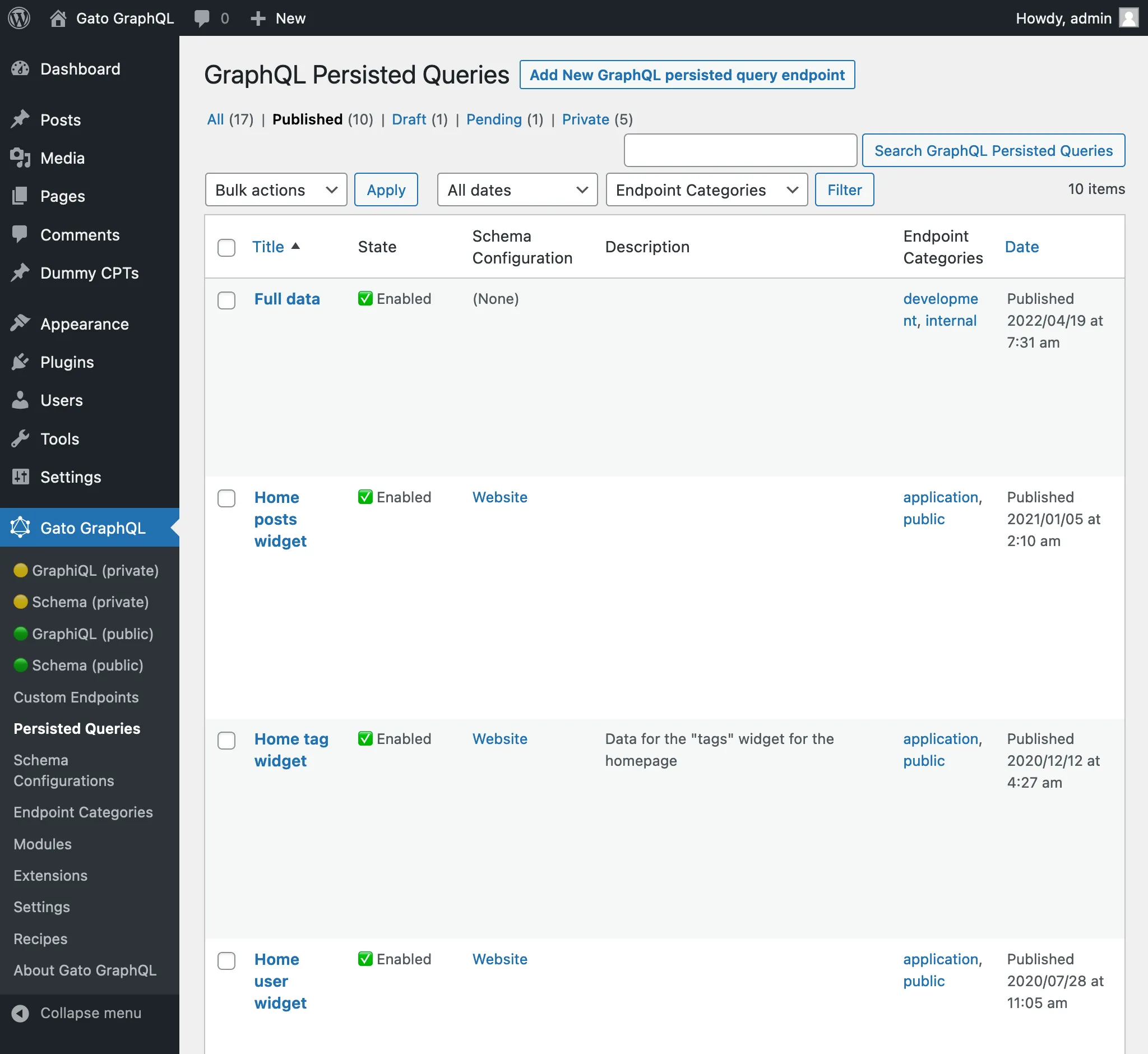
메뉴의 Persisted Queries 링크를 클릭하면 생성된 모든 persisted query의 목록이 표시됩니다:
persisted query는 커스텀 포스트 타입(CPT)입니다. 새 persisted query를 생성하려면 "새 GraphQL persisted query 추가" 버튼을 클릭하여 WordPress 에디터를 엽니다:
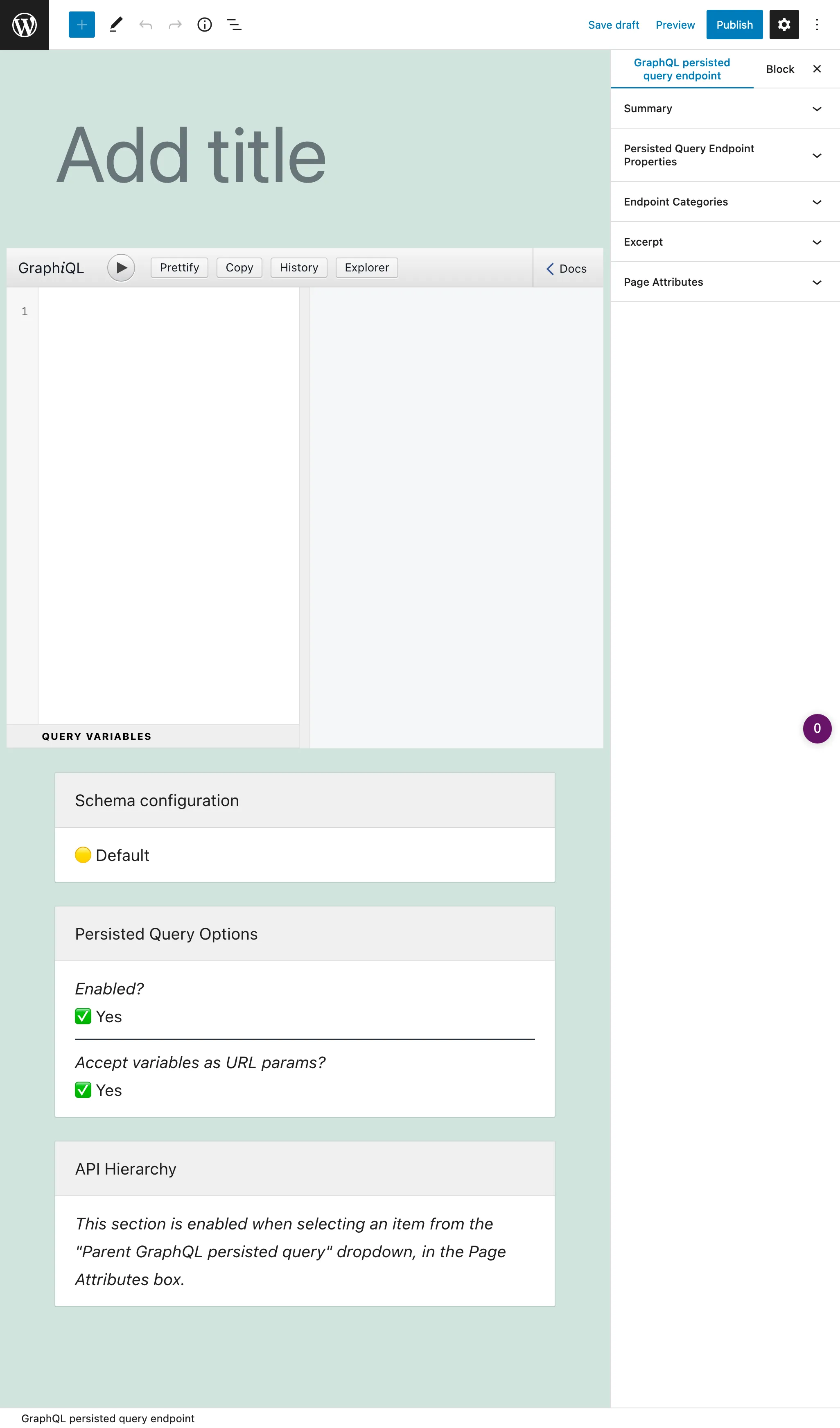
주요 입력 도구는 GraphiQL 클라이언트이며, 기본적으로 Explorer가 포함되어 있습니다. 왼쪽 사이드 패널의 필드를 클릭하면 쿼리에 추가되고, "Run" 버튼을 클릭하면 쿼리가 실행됩니다:

쿼리가 준비되면 게시하면 해당 퍼머링크가 엔드포인트가 됩니다. 엔드포인트(및 소스)에 대한 링크는 "Persisted Query Endpoint Overview" 사이드바 패널에 표시됩니다:
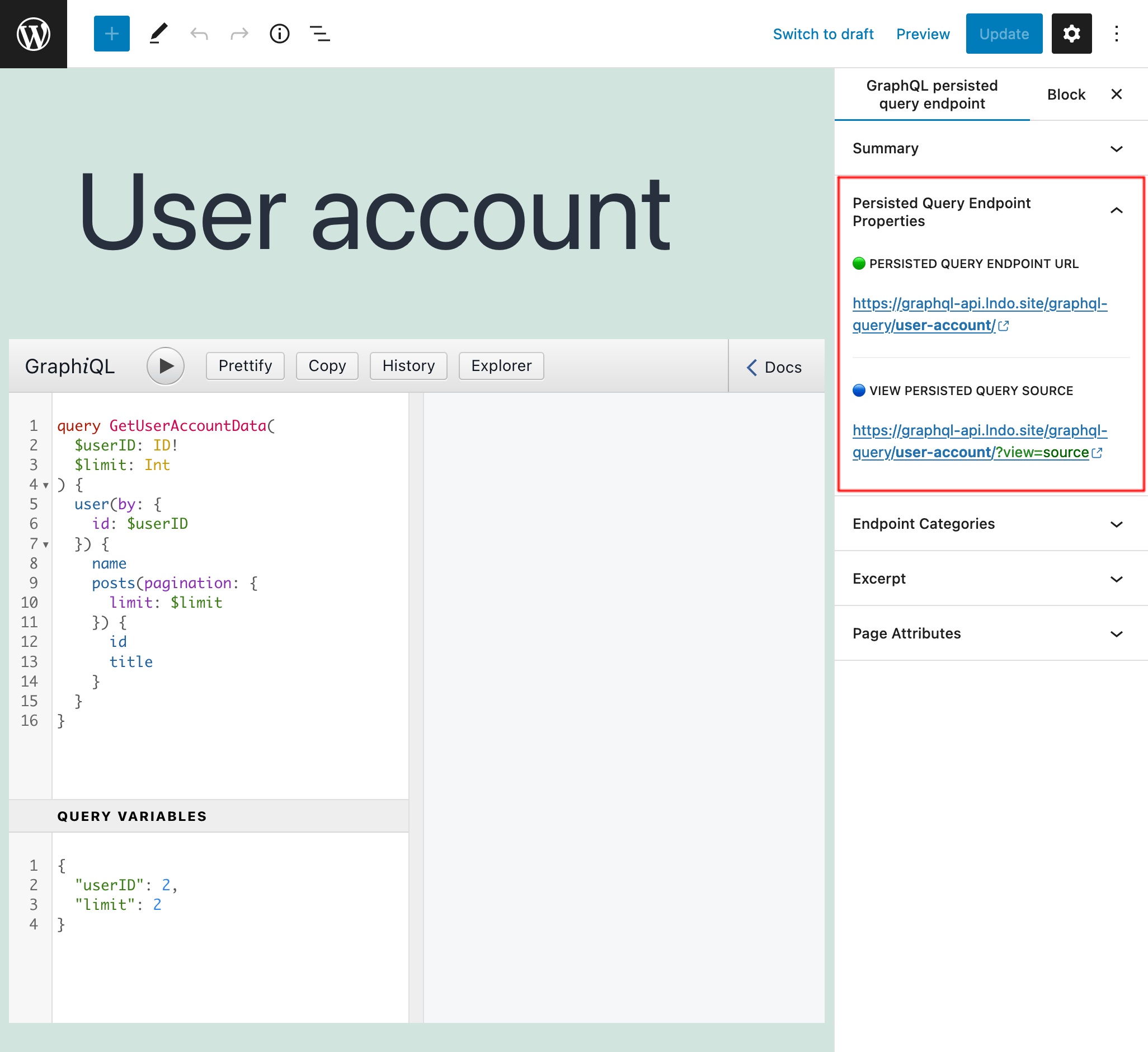
퍼머링크에 ?view=source를 추가하면 persisted query와 그 설정이 표시됩니다(사용자가 로그인되어 있고 해당 사용자 역할에 접근 권한이 있는 경우):

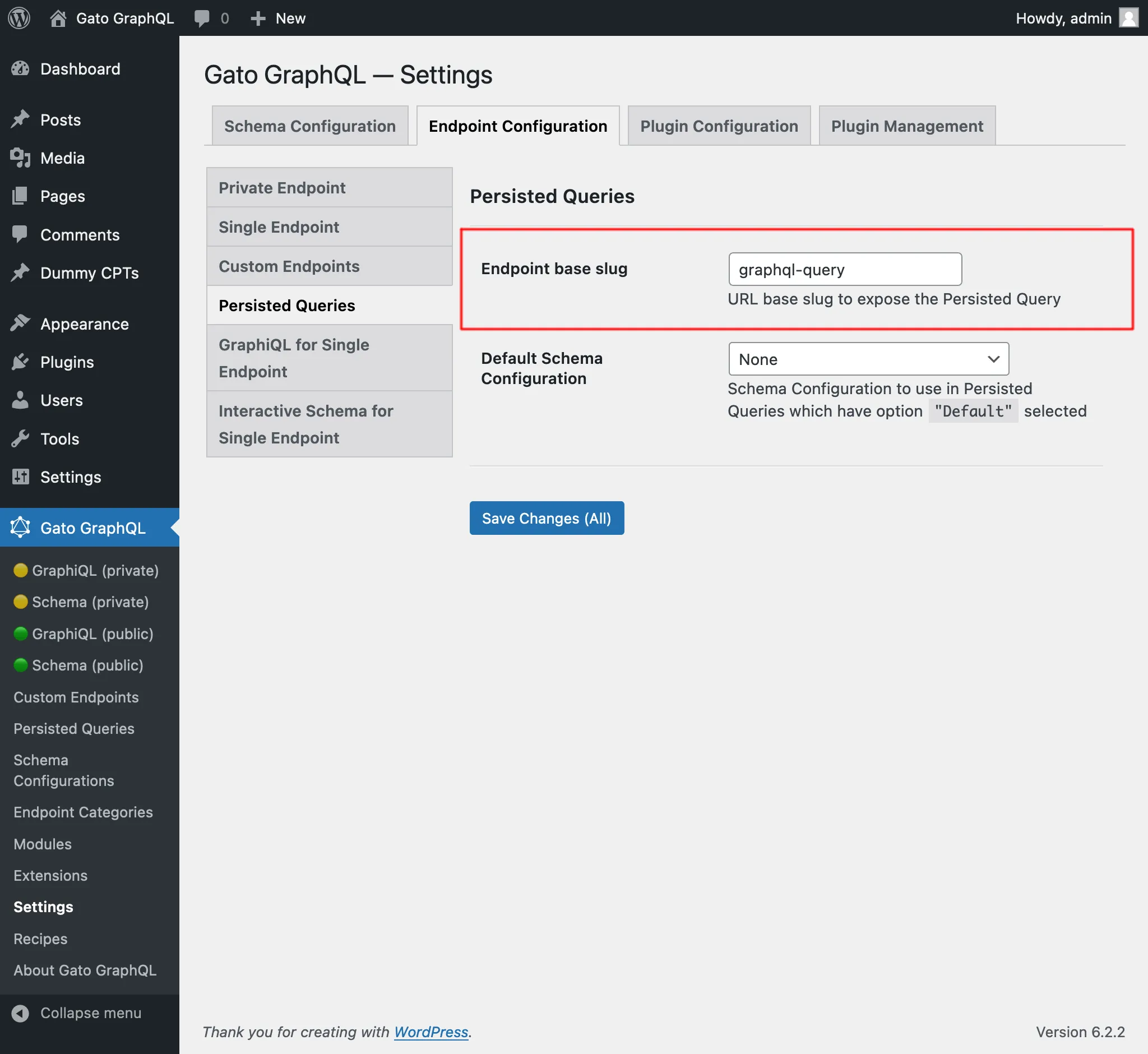
기본적으로 persisted query의 엔드포인트 경로는 /graphql-query/이며, 이 값은 Settings에서 설정할 수 있습니다:
스키마 설정
스키마에 포함되는 요소와 사용자의 접근 권한은 스키마 설정에서 정의합니다.
따라서 스키마 설정을 생성한 후 드롭다운에서 선택해야 합니다:

카테고리로 Persisted Queries 정리하기
사이드바 패널 "Endpoint categories"에서 Persisted Query 관리에 도움이 되는 카테고리를 추가할 수 있습니다:
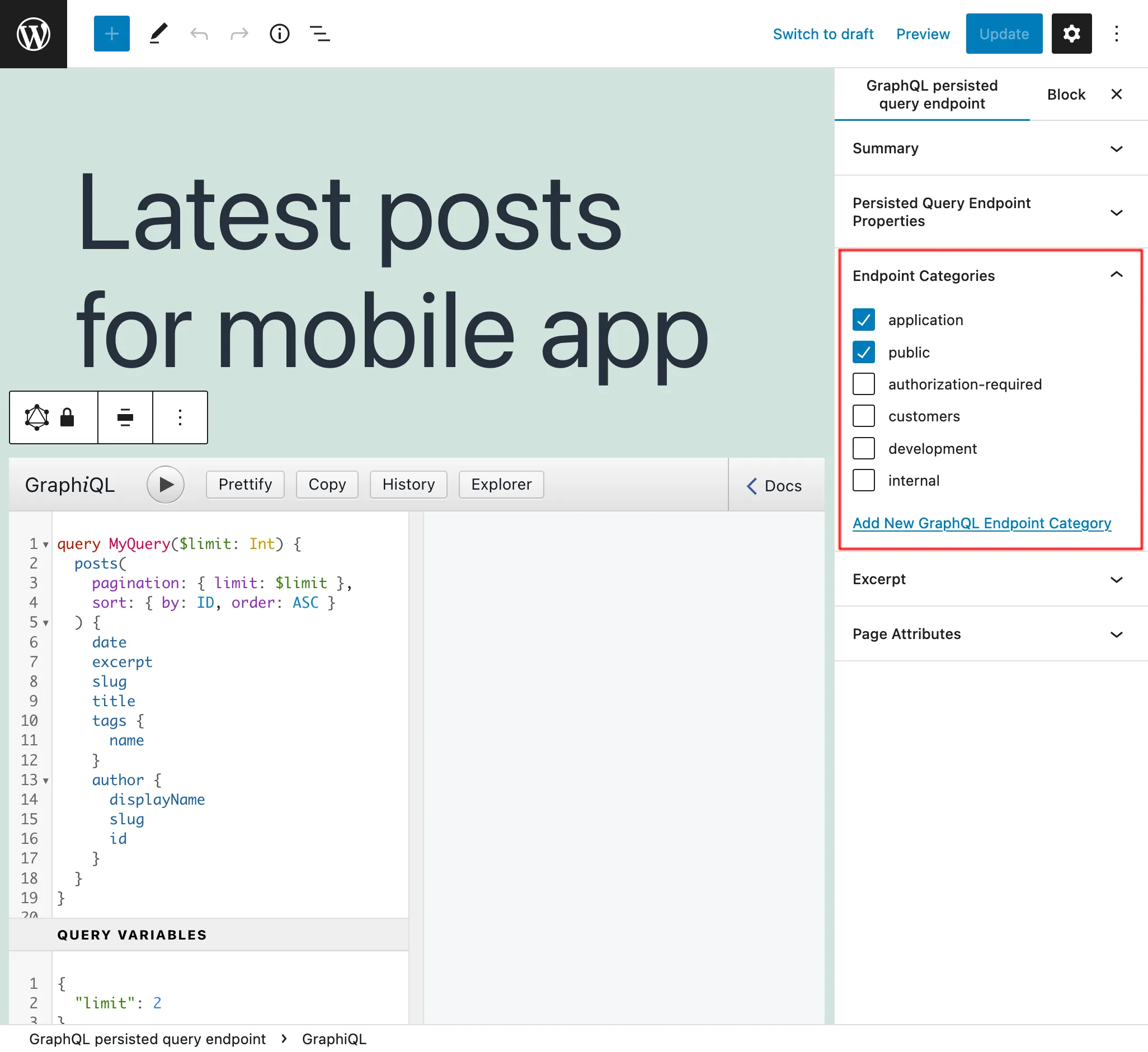
예를 들어, 클라이언트, 애플리케이션 또는 기타 필요한 정보별로 엔드포인트를 관리하는 카테고리를 생성할 수 있습니다:

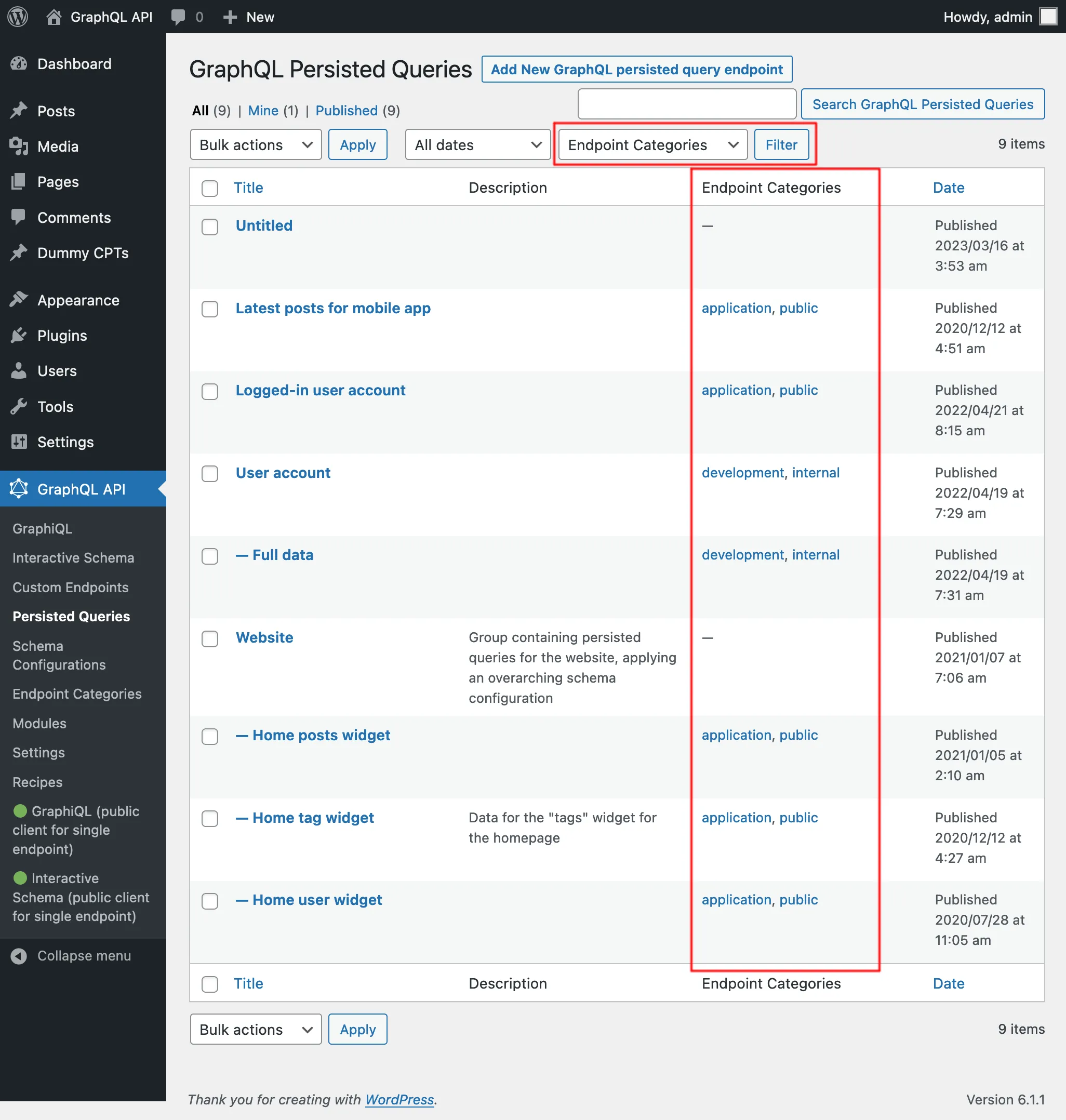
Persisted Queries 목록에서 각 카테고리를 확인할 수 있으며, 카테고리 링크를 클릭하거나 상단의 필터를 사용하면 해당 카테고리의 항목만 표시됩니다:
비공개 persisted queries
Persisted Query의 상태를 private으로 설정하면, 해당 엔드포인트는 관리자 사용자만 접근할 수 있습니다. 이를 통해 데이터에 접근해서는 안 되는 사용자에게 데이터가 의도치 않게 공유되는 것을 방지합니다.
예를 들어, 메트릭 보고서를 작성하기 위한 데이터 조회 등 애플리케이션 관리에 도움이 되는 비공개 Persisted Queries를 생성할 수 있습니다.
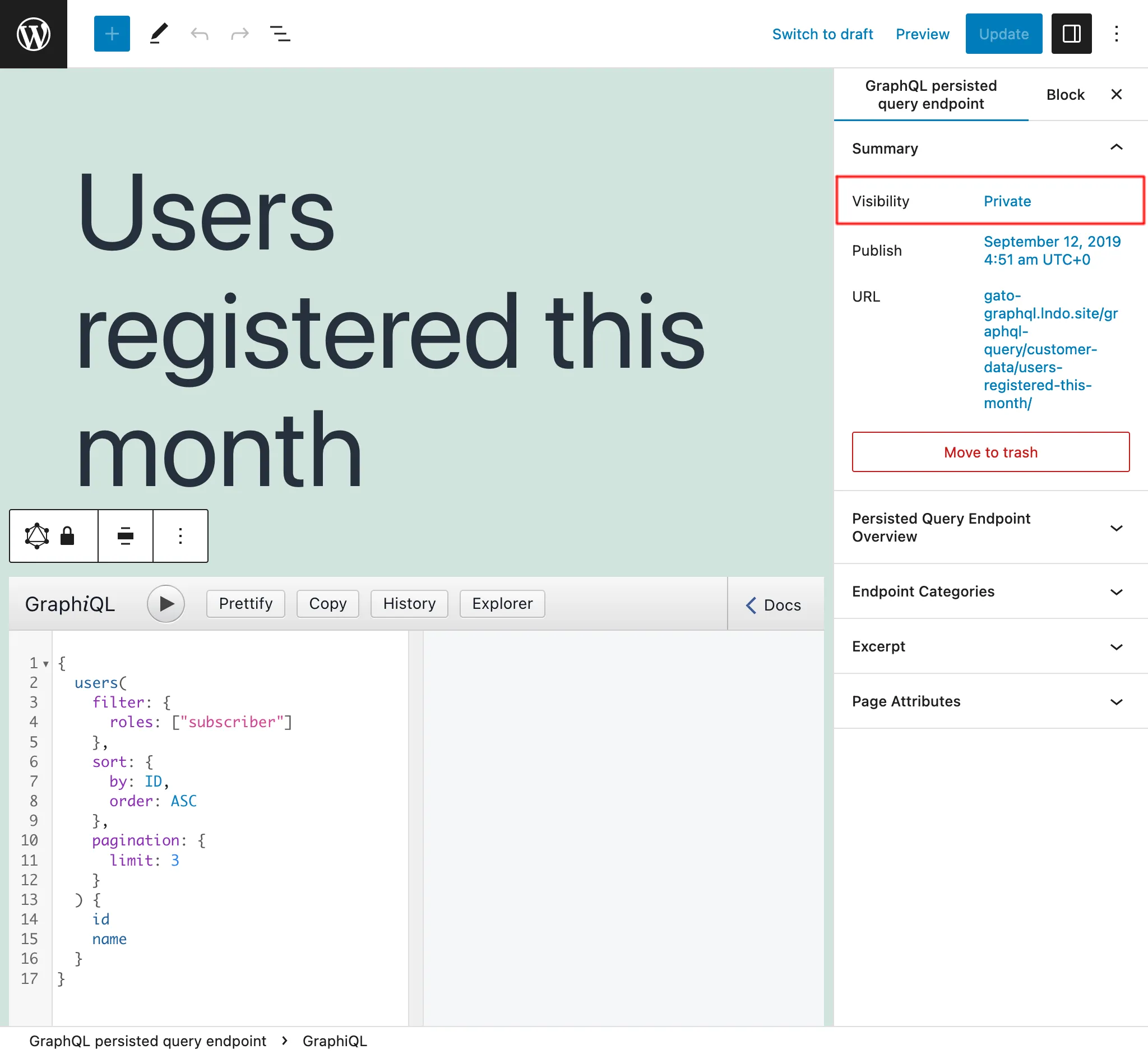
비밀번호로 보호된 persisted queries
특정 클라이언트를 위해 Persisted Query를 생성하는 경우, 비밀번호를 설정하여 해당 클라이언트만 엔드포인트에 접근할 수 있도록 추가 보안 수준을 제공할 수 있습니다.
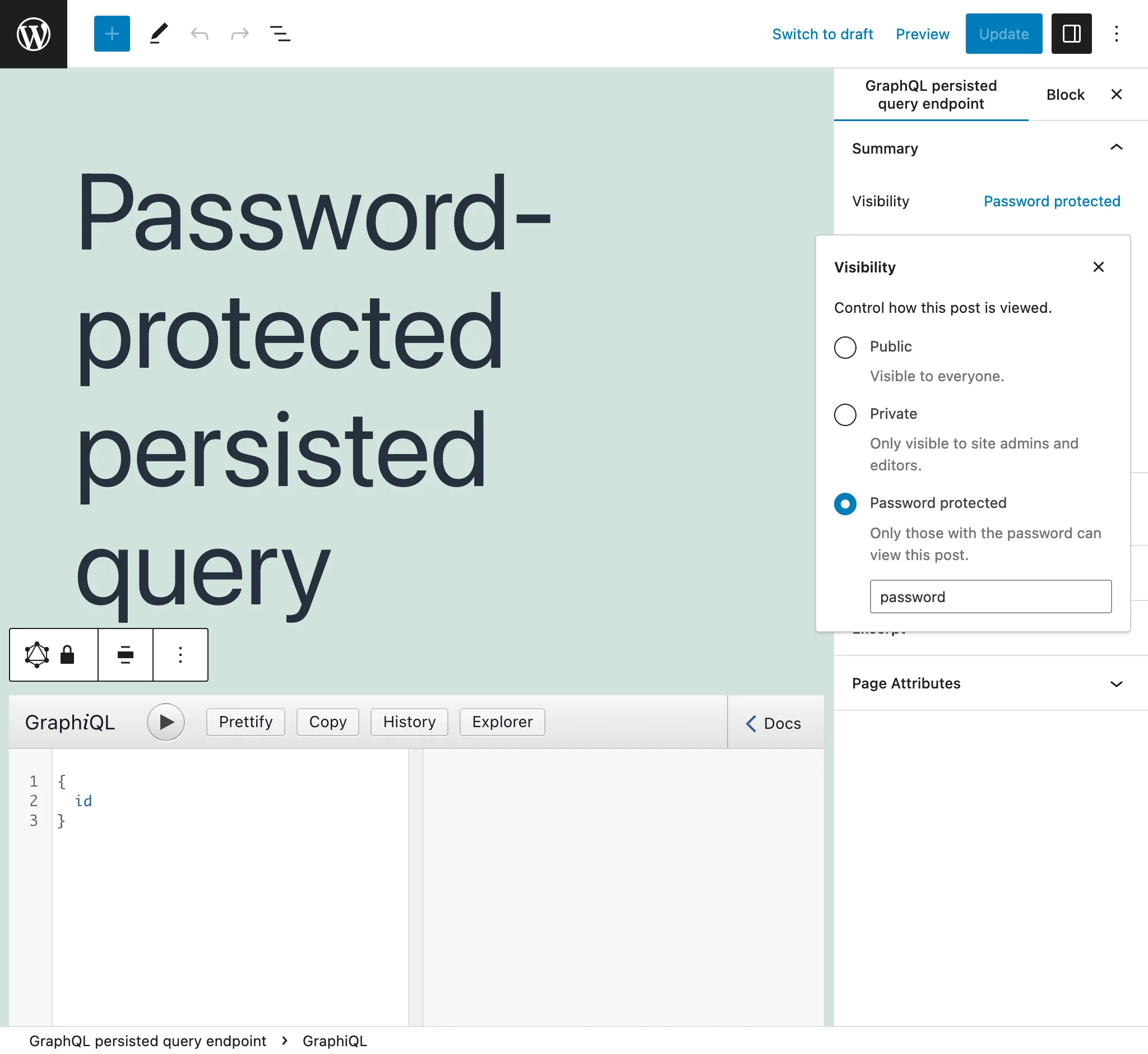
비밀번호로 보호된 persisted query에 처음 접근하면 비밀번호를 요청하는 화면이 나타납니다:
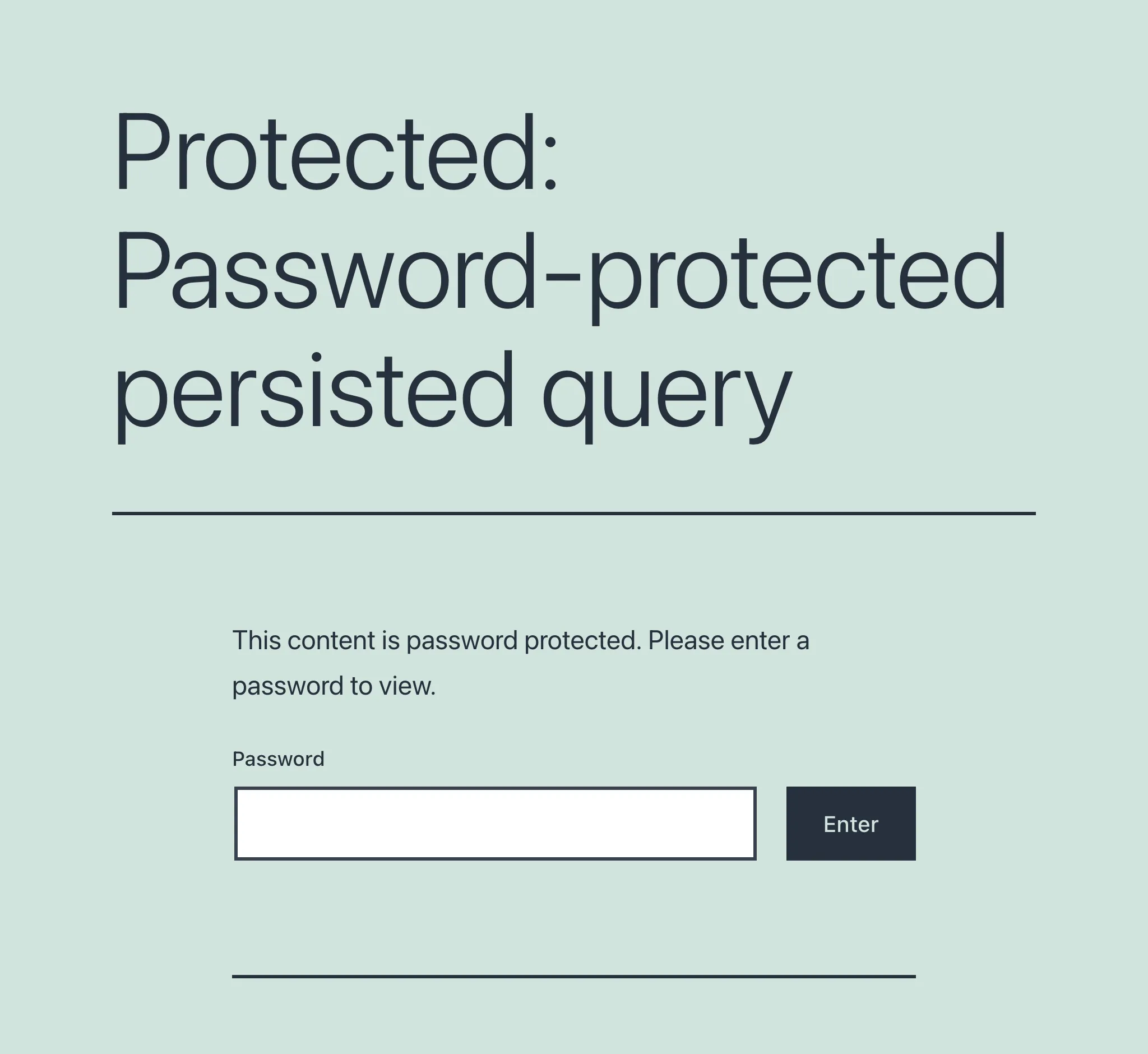
비밀번호가 입력되고 검증된 후에만 사용자는 의도한 엔드포인트에 접근할 수 있습니다.
URL 파라미터를 통한 persisted query 동적 설정
각 변수의 값은 persisted query 실행 시 URL 파라미터(변수 이름 사용)로 설정할 수 있습니다. "URL 파라미터가 변수를 덮어씁니까?" 옵션이 활성화된 경우 URL 파라미터가 우선됩니다. 그렇지 않으면 변수 딕셔너리에 정의된 값이 우선됩니다(값이 있는 경우).
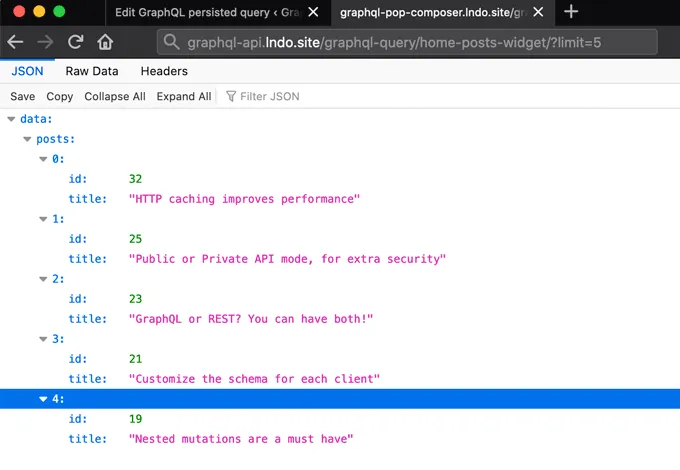
예를 들어, 이 쿼리에서 결과 수는 변수 $limit로 제어되며 기본값은 3입니다:
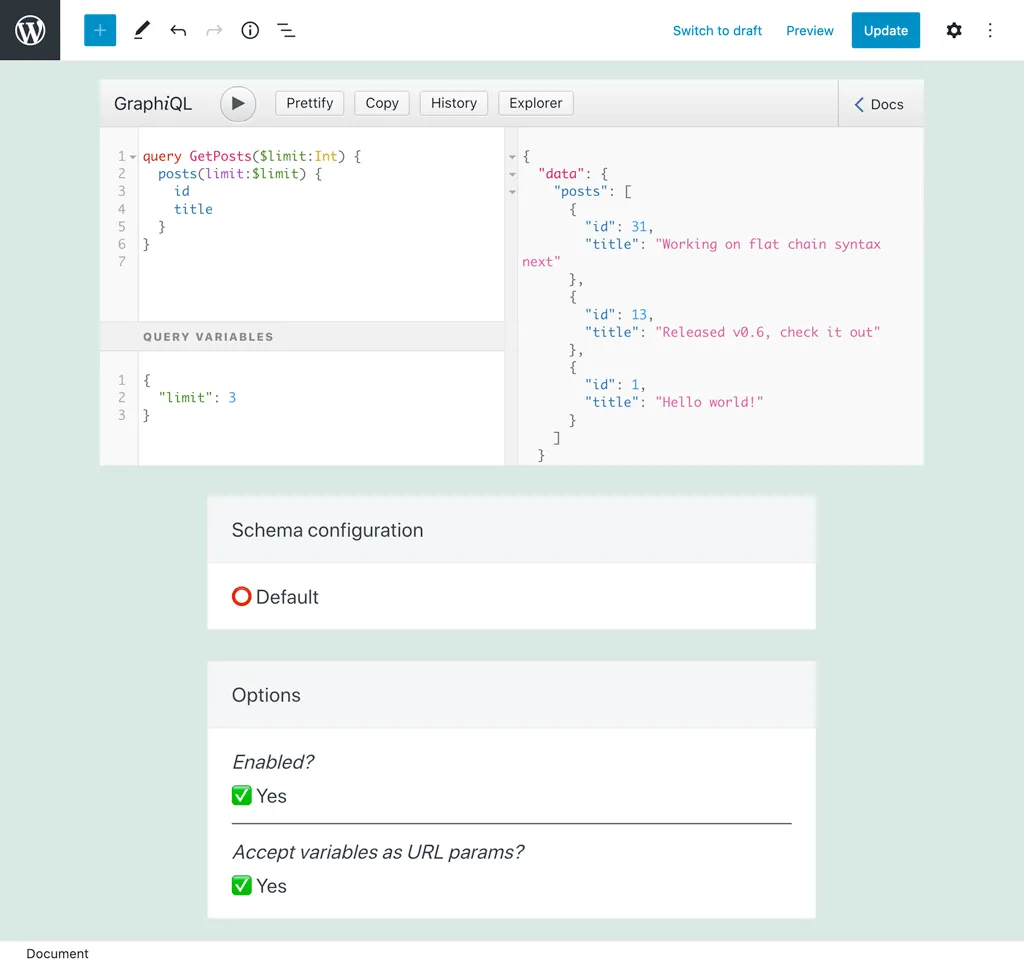
이 persisted query를 실행할 때 ?limit=5를 전달하면 5개의 결과를 반환하는 쿼리가 실행됩니다: